Dans leurs calculs, les statisticiens utilisent la loi des grands nombres. La française des jeux n’opère pas autrement pour gagner de l’argent ! Le hasard n’intervient que pour les joueurs, pas pour elle ! Les compagnies d’assurance agissent de même. Si elles assurent cent mille voitures, elles savent d’avance combien auront d’accidents et quel en sera le coût. La prime d’assurance est calculée en fonction de ce risque qui n’en est plus un dès que l’on applique la loi des grands nombres ! Si 5% des automobilistes ont un accident chaque année, vous ne pouvez prévoir si vous en aurez un. En revanche, votre compagnie d’assurance sait que, sur ses cent mille assurés, cinq mille auront un accident.
La loi des petits nombres
Les particuliers ne raisonnent pas ainsi. Si un événement malheureux mais peu probable se produit deux fois de suite à une année d’intervalle, ils se diront que jamais deux sans trois et prévoiront un troisième pour l’année suivante. A l’inverse, plusieurs années sans accident leur feront croire que plus rien ne peut leur arriver. Autrement dit, ils utilisent une loi des petits nombres et non la loi des grands nombres. Bien entendu, il ne s’agit pas de mathématique mais de psychologie !
Une question de psychologie
Pour un mathématicien, cette loi des petits nombres peut passer pour un canular. C’est pourtant de manière tout à fait scientifique et en utilisant correctement la loi des grands nombres que Daniel Kahneman l’a mise en évidence. Plus précisément, il a étudié expérimentalement le comportement moyen des américains devant l’assurance ! Il apparaît que plusieurs années sans accident pousse la moyenne des américains à résilier ses contrats d’assurance ! Pour cette étude, ce professeur de psychologie à Princeton a obtenu le Prix Nobel d’économie en 2002.
Il semblerait que certains états appliquent cette loi des petits nombres et suppriment des équipements de précaution, comme des masques de protection, quand ils se sont révélés inutiles plusieurs années de suite. D’autres, dans l’affolement, feront des tests de médicaments sur des petits nombres pour en déduire avoir trouvé le traitement miracle.
Le jeu de la vie, inventé en 1970 par John Conway, n’est pas vraiment un jeu. Ce terme est cependant moins rébarbatif que celui d’automate cellulaire, qui est pourtant plus exact. Il trouve ses origines dans des travaux conduits par John von Neumann dans les années 1940. Nous garderons la métaphore du jeu pour en parler, même si certains trouveront le terme mal adapté quand il s’agit de maladies potentiellement mortelles. L’essentiel est d’aider la compréhension. Voyons quelles en sont les règles.
Les règles du jeu de la vie
Pour jouer, prenez un damier et des pions. Les cases sont considérées comme des cellules ; elles peuvent être mortes ou vivantes. On utilise les pions pour matérialiser les cellules vivantes. Au début du jeu, on place des pions sur n’importe quelle case. On joue ensuite par étapes selon les règles suivantes :
— une cellule morte entourée de trois cellules vivantes ressuscite, sinon elle reste morte ;
— une cellule vivante reste en vie si elle a deux ou trois voisines vivantes, sinon elle meurt.
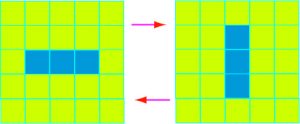
Bien que l’évolution du jeu soit complètement déterminée par la disposition initiale des cellules, on n’en assiste pas moins à quelques situations qui peuvent paraître surprenantes. Ainsi, en alignant tout simplement trois cellules vivantes les unes à côté des autres, on obtient une situation où les trois cellules se reproduisent, alignées horizontalement puis verticalement et ainsi de suite.
Lorsque trois cellules vivantes sont contiguës, on assiste à une oscillation entre trois cellules en ligne et trois en colonne.
Le jeu des épidémies
Ce jeu est loin d’être un simple amusement : il s’agit d’un exemple de ce que l’on nomme « automate cellulaire », particulièrement utile pour modéliser les processus d’expansion des épidémies comme des épizooties. En préalable à ce type d’application, il est nécessaire d’étendre le damier à l’infini. Au départ, toutes les cellules sont saines. On place une cellule infectée puis on « joue » avec la règle probabiliste suivante :
— les cellules voisines de la cellule infectée sont infectées au coup suivant avec la probabilité p ;
— la cellule meurt ou est immunisée le coup suivant.
Comment les cellules infectées (en rouge) se multiplient-elles au détriment des cellules saines (en vert) ? Dans cet exemple, la probabilité qu’une cellule voisine d’une cellule infectée soit infectée à son tour est de 25 %. Les cellules mortes ou immunisées sont représentées en bleu.
La question qui intéresse autant les épidémiologistes que le grand public est donc : « Pour quelles valeurs de p, la maladie se propage-t-elle au monde entier ? »
Un modèle probabiliste
Le modèle est ici « probabiliste », et donc on ne peut prédire à l’avance ce qui va se produire dans un cas particulier. Pour avoir une idée rapide de l’évolution moyenne du système, le mieux est de procéder à une simulation. Pour cela, on « joue » selon les règles énoncées ci-dessus en utilisant un générateur de nombres pseudo-aléatoires et on comptabilise le nombre de cellules infectées. En jouant cent fois de suite et en faisant la moyenne des résultats, on obtient une mesure de l’expansion moyenne de l’épidémie.
Taux critique
En dessous d’un certain taux de contamination p, l’épidémie ne s’étend pas. En revanche, au dessus de ce taux, elle envahit le monde entier. Dans le cadre de notre modèle simplifié, le taux critique se situe entre 30 % et 40 %. Une maladie ne devient épidémique que si ce taux est dépassé. Comment ce modèle peut-il être adapté pour bien modéliser différents types d’épidémies ou d’épizooties ? Tout d’abord, on peut modifier le voisinage de chaque cellule, composé ici de huit cellules — les spécialistes parlent de voisinage de Moore, du nom d’Edward Moore, l’un des fondateurs de la théorie des automates. On utilise souvent un voisinage plus simple, dit de von Neumann, constitué des quatre cellules partageant un côté avec la cellule considérée. Avec ce nouveau modèle, le taux critique pour lequel une maladie devient épidémique se situe aux alentours de 60 %. On peut également améliorer le modèle en tenant compte du temps pendant lequel une cellule infectée est contagieuse puis du taux de mortalité et d’immunité ainsi que du temps d’immunité. On arrive ainsi à retrouver la façon dont se sont propagées des épidémies comme la peste dans l’Europe médiévale. Une première vague a tué le tiers de la population en se propageant à partir d’un épicentre situé dans un port, suivie de plusieurs répliques plus faibles, toutes partant du même point. Ces répliques correspondent à la fin de certaines immunités.
La confrontation avec les données épidémiologiques a permis de montrer que ce type de modèles a une certaine pertinence pour toutes les maladies qui se propagent par contact direct : grippe, tuberculose, coronavirus ou même sida. En revanche, il ne fonctionne plus lorsque la maladie se propage via un agent infectieux, comme dans le cas du paludisme ou du chikungunya.
Géométrie des contagions
Comment considérer maintenant la notion de « cellule voisine » dès que l’on évoque les réseaux de transports aériens, maritimes ou terrestres ? Dans le cas d’une épidémie de grippe humaine, l’aéroport de Paris est voisin de celui de Hong-Kong. Dans le cas d’une épizootie de grippe aviaire, deux élevages fréquentant le même marché aux bestiaux sont voisins. On doit de plus tenir compte des migrations naturelles des oiseaux sauvages. Dans tous ces cas, on retrouve la notion de réseaux.
En modifiant le modèle du jeu, on peut passer du cas où chaque cellule représente un individu à celui où elle représente un domaine où les individus sont en relation constante : un élevage de volaille dans le cas de la grippe aviaire, une ville dans le cas de la tuberculose, du sida ou de la grippe humaine. Ces domaines sont reliés entre eux pour former un réseau. Dans chaque cellule, la modélisation suit une autre logique, celle du modèle « SIR » dû à William Kermack et Anderson Mac Kendrick en 1927 (voir l’article correspondant sur ce blog). Ce modèle compartimente la population en trois classes : S, la classe des individus susceptibles d’attraper la maladie, I, celle de ceux qui en sont infectés (et contagieuses) et R, ceux qui en sont guéris (et immunisés) ou décédés.
Seuil de propagation
On considère l’évolution de ces trois classes dans le temps en fonction de deux taux mesurables expérimentalement. Le premier (a) est le taux de contagion de la maladie pour un infecté, c’est-à-dire la probabilité pour qu’un individu susceptible attrape la maladie après contact avec un individu infecté. Le second taux (b) mesure le passage de l’état I à l’état R.
Après un laps de temps t, on compte aI S t infectés supplémentaires et R augmente de bI t. La variation du nombre d’infectés est donc égale à aS – b multiplié par I t. La condition pour que la maladie se propage (et donc donne lieu à une épidémie) est que le nombre de malades infectés augmente, c’est-à-dire que : aS – b > 0. Le quotient b / a a donc valeur de seuil. Si le nombre de sujets susceptibles est strictement inférieur à ce seuil, la maladie ne s’étend pas. Sinon, elle donne lieu à une épidémie (ou à une épizootie).
D’une façon qui peut paraître paradoxale, l’apparition d’une épidémie ne dépend donc pas du nombre de personnes infectées mais du nombre de personnes susceptibles d’attraper la maladie ! Cette remarque justifie à elle seule les politiques de vaccination, même avec un vaccin peu efficace.
En 1999, une jeune femme, Sally Clark, fut condamnée pour le meurtre de ses deux fils, à un an d’écart. Ceux-ci semblaient être décédés de mort subite du nourrisson. L’accusation mit en avant le rapport d’un pédiatre, qui mérite d’être nommé ici, sir Roy Meadow. Selon lui, la probabilité que deux enfants d’un même couple meurent de mort subite du nourrisson était égale à 1 sur 73 millions. D’où vient ce nombre ? Des statistiques, bien sûr. Selon elles, le risque de mort subite d’un nourrisson dans un couple aisé et non-fumeur tel celui de Sally est de 1 sur 8543. On imagine facilement d’où vient ce chiffre : on a fait le rapport entre le nombre de nourrissons morts ainsi et le nombre total de nourrissons dans ce type de couple. Le raisonnement de Roy Meadow est alors similaire à celui qui permet d’affirmer que la probabilité d’obtenir deux 6 en jetant des dés est égale à 1 sur 36. Il affirme donc que, si le risque d’un mort dans un couple est de 1 sur 8543, le risque de deux morts est de 1 sur 85432… ce qui fait bien 1 sur 73 millions environ. Le pédiatre souligna que, comme il y avait 700 000 naissances par an au Royaume-Uni, cette coïncidence ne devait arriver qu’une fois par siècle. Les jurés furent convaincus et condamnèrent Sally Clark à la prison à perpétuité.
L’art de se tromper
Pourtant, les calculs du pédiatre sont grossièrement faux. La première erreur est de ne garder chez le couple Clark que les caractéristiques diminuant le risque : couple aisé et non-fumeur. En revanche, il néglige un facteur aggravant : les enfants étaient des garçons, pour lesquels le risque est double. Enfin, quand un premier enfant est décédé de la mort subite du nourrisson, le risque qu’un second meure de même est dix fois plus élevé. Autrement dit, le calcul correct aurait dû partir de la moyenne nationale, qui est de 1 / 1300 et de le multiplier par 1 / 130. Le calcul donne maintenant un risque de 1 sur 169 000, ce qui est très différent. Le pédiatre aurait dû le savoir puisqu’un ou deux cas de morts de deux enfants d’un même couple de la mort subite du nourrisson se produit chaque année au Royaume-Uni ! Ces erreurs du pédiatre sont doublées d’une erreur fondamentale du système judiciaire : s’il est normal de confier les expertises médicales à des médecins, il devrait être aussi normal de confier les expertises statistiques à des statisticiens. Le plus humble d’entre eux aurait su montrer les erreurs grossières du pédiatre.
Les gagnants du Loto ont-ils tous triché ?
Le risque estimé de morts de deux enfants d’un même couple aisé et non-fumeur de 1 sur 73 millions fait penser à la chance qu’un joueur du Loto a de remporter le gros lot, que l’on estime à 1 sur 14 millions. Prenez le dernier gagnant, disons Candide Toutlemonde. Elle avait 1 chance sur 14 millions de gagner, doit-on en déduire qu’elle a triché ? Fait a posteriori, ce raisonnement n’a aucun sens. Il en aurait eu si, une semaine avant le tirage, vous aviez dit : « Candide va remporter le gros lot ».
Le cas de Sally Clark est similaire puisque les calculs de probabilités sont faits a posteriori. Par ailleurs, le procureur et les jurés semblent avoir interprété les calculs du pédiatre en : la probabilité d’innocence de l’accusé est de 1 sur 73 millions. Pour conclure de cette façon, il aurait fallu comparer toutes les probabilités. Au Royaume-Uni, est-il plus vraisemblable qu’une femme tue son enfant que celui-ci soit victime de la mort subite du nourrisson ? Sur les 700 000 naissances annuelles, 30 sont victimes d’un homicide, soit 1 sur 23 000 contre 1 sur 1300 pour la mort subite. La probabilité d’un double homicide est donc de 1 sur 529 millions, en suivant la logique du pédiatre, celle d’une double mort subite, de 1 sur 169 000, comme nous l’avons vu plus haut. Ce simple calcul montre à quel point l’utilisation des statistiques dans cette affaire fut erronée. Sally Clark fut acquittée en appel, en 2003, mais ne se remit jamais de ses épreuves et décéda en 2007. Plusieurs autres erreurs judiciaires sont liées à une utilisation inappropriée des statistiques. Ainsi, en 1997, Shirley McKie, une enquêtrice de la police écossaise, fut accusée d’un meurtre parce que ses empreintes digitales avaient été « identifiées » sur la scène d’un crime. Les probabilités étaient contre elle en dehors de toute autre preuve. En fait, elles n’étaient que quasiment identiques à celles du véritable meurtrier, ce qui fut prouvé ultérieurement. Ici encore, la vie d’une personne fut brisée par des chiffres.
Dans tous ces cas, le biais dans les calculs précédents est d’évaluer une probabilité par un calcul valable pour un événement qui ne s’est pas encore produit, et de l’appliquer à un événement qui s’est déjà produit. Nous pouvons rapprocher cet argument à l’existence de la vie sur Terre. L’apparition de la vie était un événement de probabilité quasi nulle, pourtant il s’est bel et bien produit puisque vous lisez ce texte écrit par un Terrien, et que vous l’êtes vous-même sans doute. Faut-il en déduire que notre existence est le résultat d’un miracle ?
Comment comprendre le monde moderne sans culture mathématique ? Accéder à celle-ci n’exige cependant pas d’apprendre à résoudre la moindre équation.